

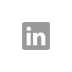

VxWorks:一个多核的长爱情故事
由米歇尔Chabroux

虽然现在谈论多核似乎很平常,但它曾经是一件大事。过去,所有的cpu都是单核的(Zylog Z80、Motorola 68K、PowerPC 8xx、386等)。CPU制造商为了提供更多的功率所做的一件事就是增加频率。最终,物理定律使其更难实现,开启了多核cpu时代。
从那以后,我们的VxWorks实时操作系统引入了许多方法来利用多核cpu带来的额外计算能力。
2001年推出的风河的第一件事是对无监督的不对称多处理的支持,通常称为AMP或UAM(见图1)。使用uamp,Bootloader会带来独立的VxWorks - 基于VxWorks的应用程序,每个应用程序并排在单个核心上运行。有效地,可以将可以在单板计算机(SBC)上完成的东西增加一倍。为了增强软件/硬件组合的价值,Wind River引入了通信机制,使VxWorks实例可以“讨论”彼此。
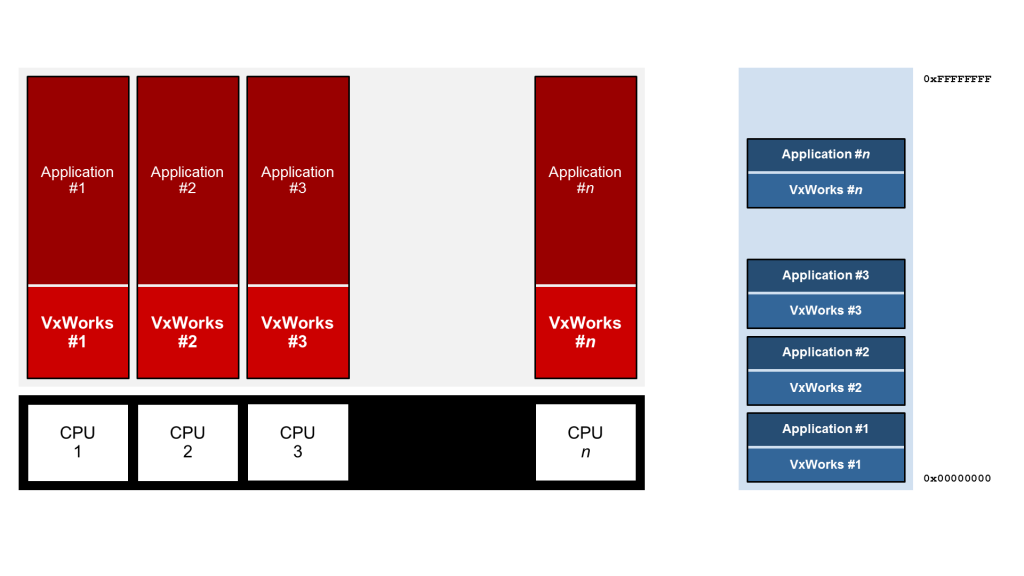
图1:AMP配置
几年后,在2007年,介绍了对对称多处理(SMP)的支持(见图2)。SMP将使用核心远离用户的负担转移到操作系统。实际上,这是使用负载均衡器完成的。使用VxWorks,负载均衡器使用最高的基于优先级的计划程序,该计划旨在最有效地使用所有内核。
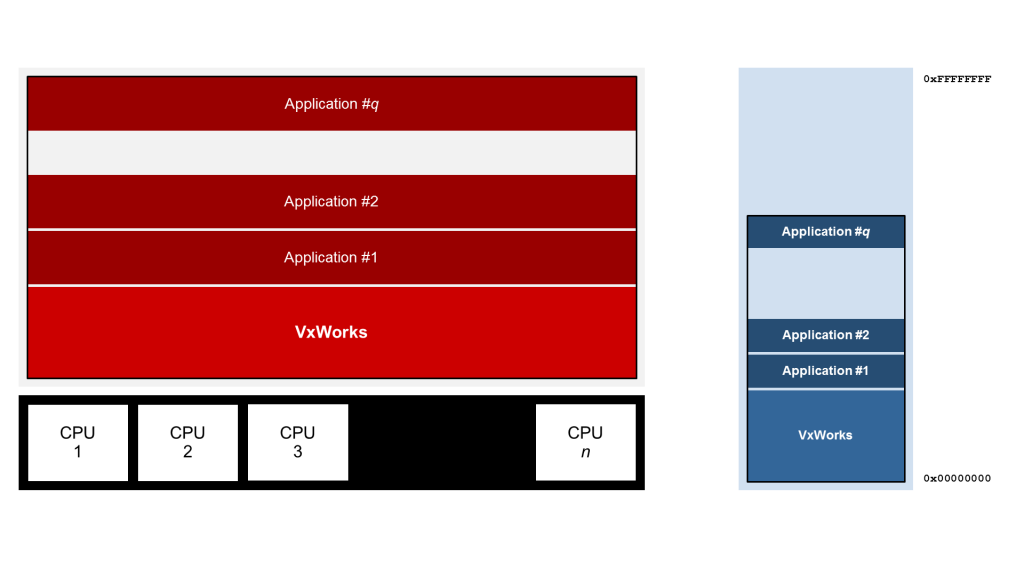
图2:SMP配置
随着CPU制造商越来越有创造性地提供更多的计算能力,超线程等概念被引入。这意味着一个核心有硬件线程的形式——通常是2个。因此,一个双核CPU提供对4个虚拟核的访问。VxWorks的负载均衡器透明地利用了这些虚拟核,使得应用程序很容易伸缩。
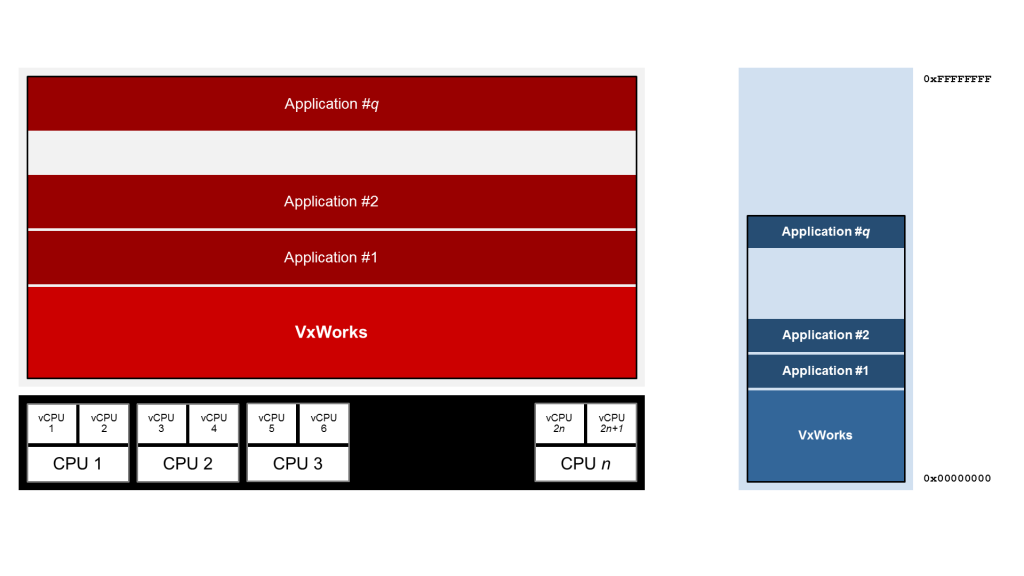
图3:带CPU线程的SMP配置
在最近的过去,在一些OS中引入了一种新的混合多处理概念,有时被称为绑定的多处理(BMP)。虽然在VxWorks的情况下不是新的,但由于它已经存在自版本6.6,这是一种有趣的方法。该想法是使用SMP中配置的单个操作系统,但在核心上使用亲和力“分区”线程。这种方法可以像一种监督的放大器(SAMP)的形式。
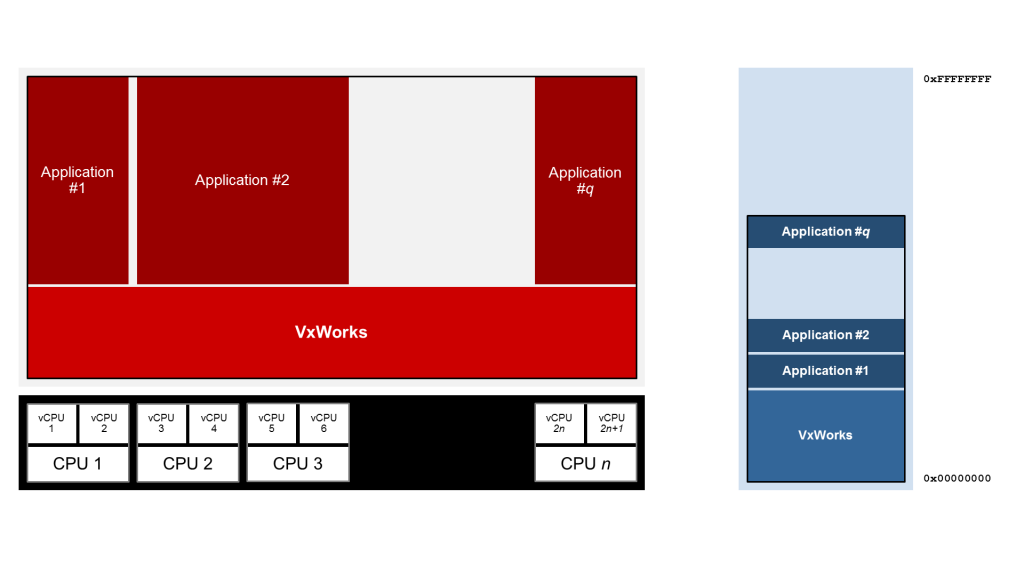
图4:BMP配置
使用VxWorks,我们使用更经典的描述来获取此方法称为亲和力。实际上,使用VxWorks,每个线程都可以配置为在特定核心上运行,或者您可以让调度程序决定。此分配称为任务的CPU亲和力。
使用SMP的默认配置通常提供最佳的整体负载平衡。但是,存在将特定任务集分配给特定CPU的情况可能是有用的。例如,如果CPU专用于处理某些数据并且没有其他工作,则缓存仍然填充了该活动所需的代码和数据。这节省了潜在的宝贵时间,用于将一个线程“移动”到另一个CPU;即使在单件芯片内也被产生,因为L1高速缓存绑定到单个CPU,如果任务迁移到不同的CPU,则必须使用新文本和数据重新填充L1。
为了进一步推动这一概念,VxWorks还支持中断CPU亲和力。在这种情况下,可以将特定的中断路由到特定的核心,使应用程序能够更多地控制它们如何利用硬件。
当我们始终尝试提供最大的灵活性时,VxWorks也会为表带来线程继承父级属性的功能(创建它们的线程)。这使得用户空间应用程序能够,因此所有的线程也可以固定到核心。
最后,为了完成图片并真正实现SMP和sAMP的混合,VxWorks也支持CPU的预订。使用CPU预留,调度程序将永远不会尝试使用线程预留的核心。这可以防止专用线程被系统中的其他线程抢占,从而进一步提高性能。
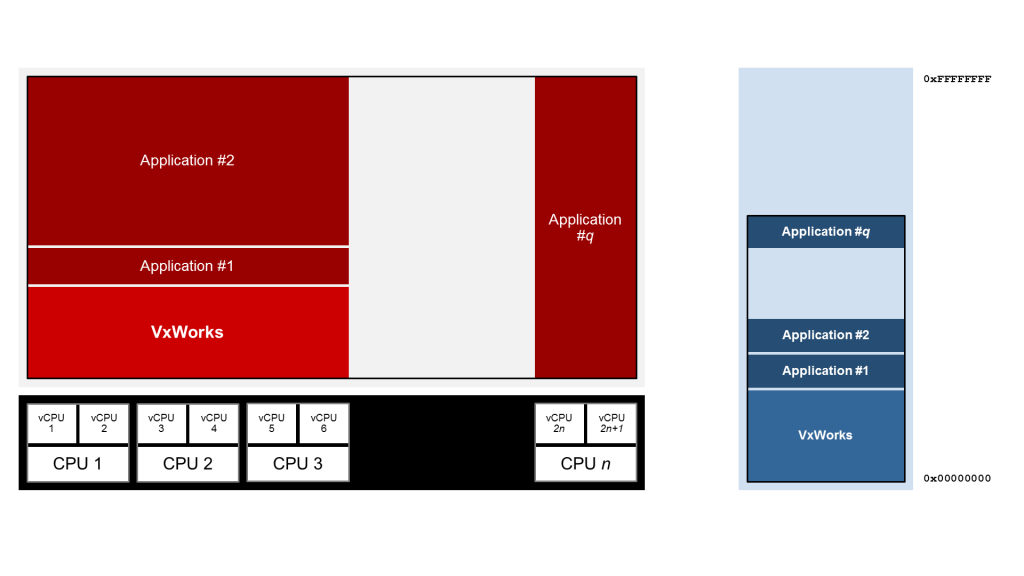
图5:SMP配置和CPU预留
如果我们不支持真正的虚拟化支持的监督放大器,我们的亲和力(没有双关语)不会完整。跟我们螺旋虚拟化平台利用我们的ARINC 653航空电子DO-178C DAL A认证平台,用户可以利用完全分离的力量在VxWorks提供的所有其他可能的选项之上。
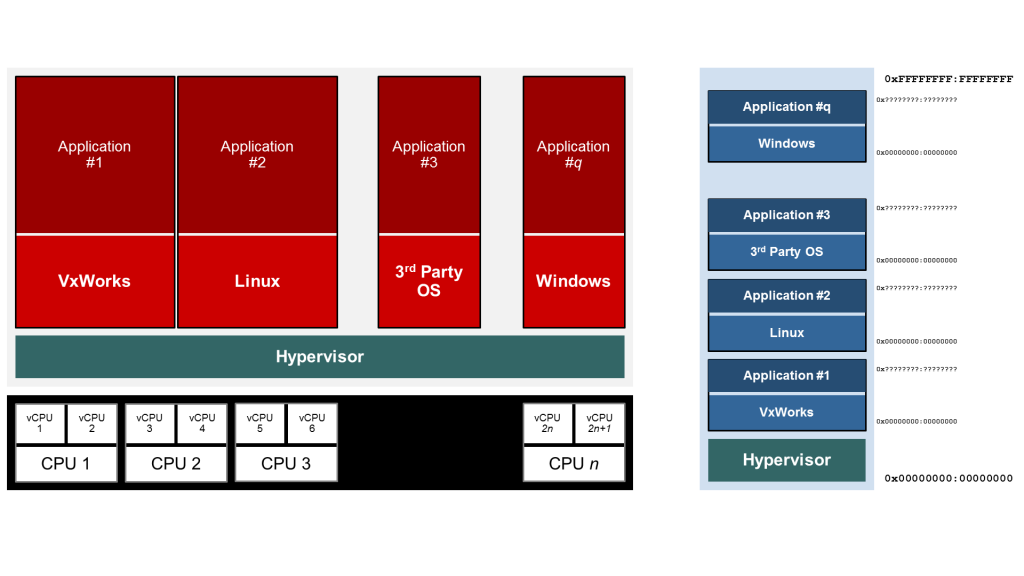
图6:基于虚拟化的配置
如果您有任何需要用VxWorks推动多核系统的边界,我们有您需要的一切:SMP、BMP、uAMP、sAMP以及介于两者之间的一切。