



用《100万模拟人生》调查非核心错误弹性:hyhymin Cho访谈
由雅各布Engblom

与Simics合作的一大好处是,我们可以了解到使用该工具的新方法。这篇博客中的采访提供了这样一个例子——hyhymin Cho,斯坦福大学的一名博士生,正在使用Simics系统地研究硬件和软件中的错误恢复能力,到目前为止已经运行了100多万次Simics。这是一个惊人的数字。Simics的设置也非常有趣,包括用于在门级模拟硬件的RTL模拟器,以及用于到达运行的有趣部分的检查点,以及广泛的自动化。令人惊叹的东西,我希望你们会像我一样喜欢学习这些知识。
Jakob Engblom:请介绍你自己!

Hyungmin曹我是赵亨明,斯坦福大学的博士生。我是健壮的系统集团,我的导师是教授Subhasish Mitra。
我:您目前研究的主题是什么?
HC:我们正在研究各种硬件可靠性问题,包括软错误、电压不稳定和电路老化问题。在这项工作中,我们着重于硬件逻辑组件上的软错误。我们首先描述这些软错误的应用程序级影响,并提供有效的解决方案来保护系统免受软错误的影响。为了提供经济有效的解决方案,我们探索跨层解决方案,在多个系统设计层(例如,电路、架构和应用层)上结合错误保护技术。
实际上,对处理器核心错误的研究很多。然而,很少有人关注所谓的“非核心”组件,如内存子系统的逻辑组件或I/O控制器。在现代芯片上系统(soc)中,这种非核心组件占用的面积和功耗与处理器核心相当。利用Simics模拟器的仿真能力,研究了大型soc非核心器件的软误差。
我:在非核心部分完全同意。这显然是我们前进的方向,将越来越多的功能聚集到单个芯片上。无论如何;到目前为止你有什么有趣的结果吗?
HC:我们有了内存子系统错误的初步结果。我们发现非核心组件上的软错误需要特别注意,因为1)它们对系统级的可靠性有显著影响,2)现有的错误保护技术对非核心组件是不够的(例如,不能满足安全要求)。我们还在努力扩大我们的研究重点,以涵盖其他类型的非核心组件,特别是I/O组件。
我:要清楚的是,软错误是只改变一次系统状态,但不是永久的错误?
HC:是的,错误的主要原因是辐射,如阿尔法粒子或宇宙射线。对于大规模数据阵列,如高速缓存SRAM或DRAM,有效的纠错编码(ECC)技术被广泛用于解决软错误。然而,对于逻辑组件,很难提供低成本的错误保护机制。因此,正确理解错误的应用层效应,探索跨层错误弹性技术是非常重要的。
虽然主要的焦点是软错误,但我们也研究其他类型的硬件错误。利用该平台,我们还模拟了各种故障模式,如电压下降和延迟故障,甚至永久性故障。
我:你如何在你的研究中使用Simics ?
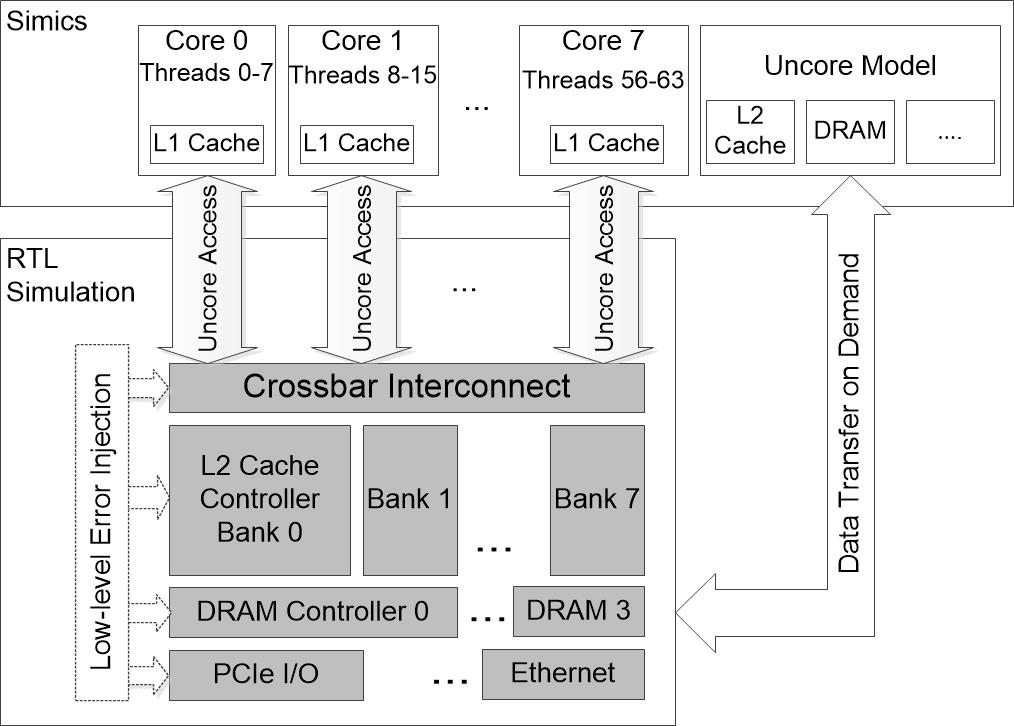
HC:研究非核心部件的难点之一是在保持仿真精度的同时对大型系统进行精确建模。非核心组件,如共享L2缓存控制器或交叉互连,连接到多个处理器核心和其他非核心组件,一个非核心组件的错误行为可能会影响系统中的多个其他组件。因此,我们需要建立一个完整的系统模型,以正确地观察非核心组件错误的影响。我们以OpenSPARC T2 SoC设计为例进行模拟,该设计在其8个处理器内核中支持64个硬件线程以及各种非核心组件。为了模拟这样一个具有现实应用的大规模系统,需要快速的仿真能力。然而,现有的大规模系统仿真技术不能准确地建模低级错误,如硬件组件中的位反转。另一方面,RTL仿真在使用真实应用程序建模全尺寸SoC时非常缓慢。例如,OpenSPARC T2设计的RTL仿真只能模拟每秒100个周期。
我们的解决方案是将Simics连接到一个低级RTL模拟器。系统的其余部分在Simics上进行仿真,而误差注入目标在RTL模拟器中进行仿真。对目标非核心组件的任何访问都将被捕获并重定向到RTL模拟器,而来自非核心组件的响应将被发送回Simics。错误注入建模完成后,Simics断开慢速RTL仿真,继续完成应用程序执行,观察注入错误的应用级效果。
我:因此,本质上,您在RTL内部运行模拟,直到所有的效果都传播到内存内容,然后切换回快速模拟?
HC:是的,我们创建Simics模块来执行对非核心组件的快速高级模拟。这些高级模型在功能上与实际的RTL模块相同,但是它们没有为错误模拟建模低级细节。然而,一旦我们能够将传播错误的影响映射到模拟的高级状态,就不再需要缓慢的RTL模拟,我们可以继续进行快速模拟。
我:注入错误对应用程序执行有什么影响?
HC:根据应用程序的领域,错误的影响可能有不同的含义。作为一般规则,我们将应用程序级结果分为五类。
- 消失了:注入错误不会影响应用程序的最终输出。
- 输出不匹配:由于注入的错误,应用程序产生一个不正确的输出,但没有明确的错误指示报告给用户。这种类型的错误也称为静默数据损坏(SDC)。由于用户没有意识到输出已损坏,这可能是需要注意的最关键的错误类型。例如,IBM的目标是每个系统每1000年不超过1个未检测到的错误。
- 输出不受影响:注入的错误破坏了系统的一些架构状态,但是应用程序的最终输出是没有错误的。然而,这种类型的错误有可能产生不必要的副作用。
- 意外终止:应用程序失败,并显示错误指示,如应用程序崩溃,操作系统内核恐慌,或应用程序退出与错误代码。
- 挂:即使在指定的超时限制之后,应用程序也不会生成输出。
这种分类就是一个例子,软错误会以各种方式影响系统的可靠性。例如,输出不受影响的错误类型可能会改变交互式应用程序的用户体验,即使最终输出是正常的。
我:我印象中你正在用Simics做大量的测试?
HC:是的,为了获得统计上显著的结果,我们需要大量的误差注入样本。基本上,我们不能模拟所有可能的错误场景(错误注入目标x错误注入时间),这远远超过10^14的情况。相反,我们随机抽样了大量的错误注入场景,这些场景可以为我们的结果提供合理的信心。对于每个错误注入目标组件,我们在基准测试套件中对每个应用程序进行了至少40,000次随机错误注入。到目前为止,我们总共产生了100多万个错误注入运行。
我:100万次试验,可够多的了。通常每次跑多长时间?
HC:如果我们从开始到结束运行PARSEC基准应用程序,则错误注入运行需要超过24小时。因为我们也在《Simics》中模拟了非核心模型,所以我们的设置需要更长的时间。为了减少开销,我们使用了许多策略。例如,由于我们只需要对注入的错误如何影响应用程序进行建模,一旦我们观察到注入的错误消失了,并且没有任何错误传播,我们就不需要模拟应用程序的其余部分。此外,我们不必每次都从应用程序的开始模拟执行。使用我们在一次性无错误执行期间创建的Simics检查点之一,我们可以跳过模拟工作,直到每次运行的实际错误注入时间。因此,如果错误影响有限,则错误注入运行只需几分钟,但可能需要几个小时来为某些错误注入实例完全建模应用程序效果。平均来说,一次错误注入运行大约需要10分钟。
我:我知道你产生了一系列检查点在试运行期间,然后从这些检查点中的一个开始你的实验?这是一个很好的技巧!你为每个基准设置了多少个检查点?
HC:我们每100万个周期创建一个检查点,一个基准测试应用程序平均有大约1000个检查点。每个错误注入运行的存储需求和开销之间都存在权衡。我们发现,在每个运行时,低于100万个周期只会带来很小的好处,因为其他开销源开始占主导地位,比如启动并连接到RTL模拟器。
我:你如何开始这些跑步?我猜你没有用手跑过一百万次吧?
HC:我们使用BASH和Python脚本并行实例化多个错误注入运行,并处理输出日志。
我:有多少个实验可以并行运行?
HC:多亏了西米奇大学项目,我们能够获得足够的错误注入运行许可证。目前,我们正在服务器上并行运行150个实例。当前的瓶颈是RTL模拟器的许可证数量。
我:如果人们想要阅读更多关于你的研究结果,他们可以去哪里?
HC:关于这个项目我们没有发表过论文,下面是一些相关链接
- http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6560694-本文是我们之前讨论处理器内核错误注入技术(仅RTL仿真)的工作之一。
- http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6651907-本文是我们小组使用Simics在大规模cmp上运行应用程序的另一个例子。
我:谢谢,非常有趣!