



Simics 5多核加速器——提高性能,增加并行性
由雅各布Engblom

最重要的新闻之一西米奇5是多核加速器。利用多核加速器,我们可以使用一个多核主机来模拟一个紧密耦合的多核目标。自从Simics 4.0在2008年发布以来,Simics已经能够在多个主机核上模拟多个离散的目标机器或机架,Simics 5将此带到逻辑上的下一步,拆分电路板和soc。
执行方法的逻辑进程如下图所示(是的,这个图也显示在《Simics 5》的原始公告):
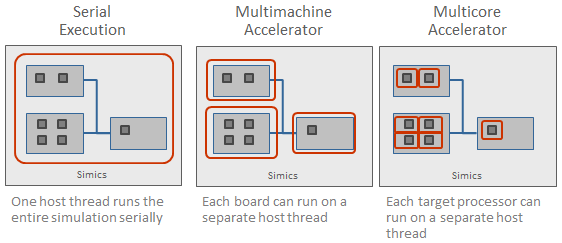
A我们可以看到,关键是将目标系统分割成越来越小的部分,以确保我们能够更快地完成工作负载中最需要计算的部分。多机加速器在很多情况下都能很好地工作,但如果我们的系统是一个单一的重载多核SoC在关键路径上,它基本上就会回到串行执行。有了多核加速器,现在可以在多个主机线程之间分割工作负载,加快执行速度。这是一个非常简单的想法,但却很难有效和正确地实现。
值得指出的是,尽管多核主机是Simics accelerator的关键推动者,但我们实际上是在多个主机上运行Simics线程在工作人员集中安排中。目标内核不需要静态地分配给主机内核,而是动态地调度可用主机线程上的计算工作。该系统有相当多的层,如下图所示:
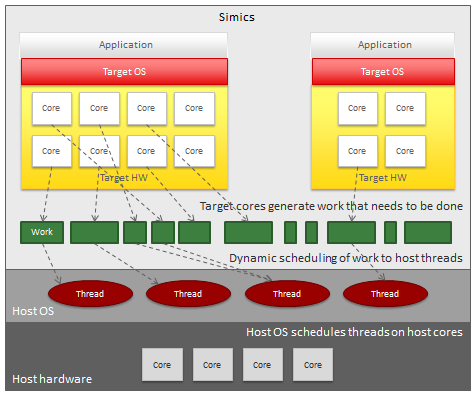
了解目标内核是如何生成模拟工作的,这些模拟工作的大小取决于它们的当前负载,然后通过Simics动态调度机制将这些工作调度到主机线程上。然后主机操作系统在硬件内核和超线程上执行主机线程。
那么,它的可扩展性如何呢?很好,真的。有许多类型的工作负载、目标、目标操作系统和内存系统需要研究,但是对于计算限制的工作负载,当在一个有8个可用来运行Simics的真实核的主机上模拟8核Linux SMP目标时,我们看到几乎是线性扩展(7倍加速)。在我个人的实验中,我经常在一个简陋的Haswell Core i5上实现2倍的加速(2核2线程),在Core i7上接近4x(4核2线程)。
因此,我们可以看到,MCA提供了提高模拟性能和伸缩性的能力,以解决曾经是模拟的瓶颈的工作负载。它不是万灵药,但当多核目标处于关键模拟路径上时,它是一种非常有用的附加性能技术。即使对于像操作系统引导这样的主要串行工作负载,我们也看到过一些并行的情况——多核加速器提供了25%左右的加速,这仍然非常有用。
通过使用MCA,您可以了解到一些有关性能的有趣事情。并行性和并行性能真的不是那么容易理解,特别是难以预测。
特别引人注目的是,目标在basic Simics JIT上运行得越好,(Intel体系结构)主机上的超线程的价值就越低。似乎会发生这样的情况:当目标工作负载与JIT编译器很好地工作时,JIT编译器将创建很少有管道暂停和缓存遗漏的代码,并使处理器管道保持忙碌。由于有许多这样的线程并行运行,超线程就不会利用任何漏洞。记住,在当前硬件、核本质上是两个指令流共享相同的执行核心,通常工作很好因为大多数代码会缓存缺失和其他“阻塞事件”,其他hyperthread可以进入并保持管道工作(从而提高性能显著小额外硬件资源的投资)。在《模拟人生》中,这种有益的情况似乎相当罕见。核有时加快速度,但是,正如他们似乎绊倒对方的脚在他们急于把事情通过基于目标运行的管道,使用2主机线程时的速度比使用4主机线程双核,2-threads-per-core Core i5。这里矛盾的事实是,如果基本JIT的工作做得不好,MCA的伸缩性会更好,因为超线程会有更多的空闲时间来利用——但总体性能当然会更差。有趣的东西。
从用户的角度来看,需要注意的是,每个处理器体系结构都需要单独启用多核加速器,因为目标并行同步语义必须映射到主机原语。在发布时,Simics 5支持英特尔、ARM和Power架构。
多核加速器不是确定性的,不像已建立的多机加速器。为了最大化性能,这是一个必要的权衡,因为确定性实现会遭受明显的性能损失。在实践中,这意味着为了使用Simics反向调试和重播调试,您需要在没有MCA的情况下运行——使用MCA来定位工作负载并通过大量代码,然后使用标准Simics来分析和调试。
提高性能在模拟中总是很重要的,因为性能决定了什么样的软件负载可以在交互式使用给定的时间框架内在模拟中有效地运行,自动测试,或持续集成回车场。